
tg-me.com/knowledge_accumulator/215
Last Update:
XLand-MiniGrid: Scalable Meta-Reinforcement Learning Environments in JAX [2024]
Одной из главных компонент обучения общего интеллекта будет обучающее распределение задач. На мой взгляд, оно не обязано быть сложным и высокоразмерным, главная необходимая характеристика - это высокое разнообразие задач. XLand-MiniGrid является движением именно в эту сторону.
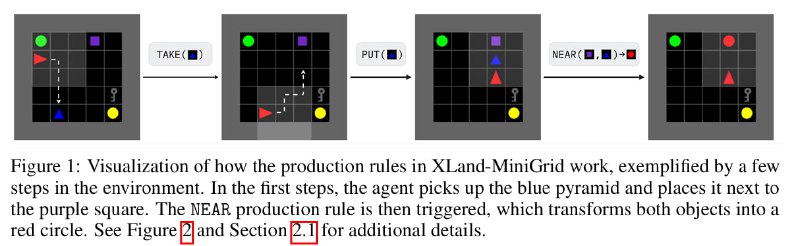
Существует такая среда XLand, на которой тренировали AdA. Каждая задача представляла из себя случайную 3Д-комнату, на которой были разбросаны объекты. Агент управлялся от первого лица, получая изображение на вход. При создании задачи сэмплировался набор "правил" - то, как между собой взаимодействуют объекты, разбросанные по комнате. Например, если два определённых объекта касаются друг друга, то вместо них появляется определённый третий.
Несколько простых правил порождали ~10^40 возможных задач, на которых потом обучали мета-алгоритм. Авторы XLand-MiniGrid применили похожий подход, но вместо 3Д-комнаты используется небольшая 2Д-сетка, таким образом убирается лишняя сложность и уменьшается требуемый компьют. Сейчас самое время взглянуть на иллюстрацию.
Существует процедура генерации задачи - строится дерево "подзадач", каждая из которых - "получение" определённого объекта из полученных ранее (засчёт правил превращения). Финальная цель - получить объект в корне этого дерева. У дерева можно регулировать разнообразие и количество вершин, таким образом задавая сложность.
Среда реализована в JAX и позволяет эффективно гонять её на GPU, запуская много сред одновременно, что уменьшает вероятность нахождения боттлнека в симуляторе.
Минусом в этой среде, на мой взгляд, является не особо большое концептуальное разнообразие правил взаимодействия объектов в этой среде - по факту они все сводятся к нахождению рядом между собой 2 объектов, либо к держанию агентом объекта. Реальная ли эта проблема? Неясно, потому что ещё непонятно, насколько именно разнообразным должен быть класс задач, на котором мета-обучают интеллект.
Кажется, что эволюция обучающих сред должна происходить совместно с эволюцией мета-алгоритмов, и все они должны двигаться в сторону общего интеллекта. Под этим я имею ввиду, что необходим какой-то meta-RL-бенчмарк - задача, на котором не запускают мета-обучение, а только мета-тестируют итоговый обучающий алгоритм. Это бы позволило исследователям соревноваться на одном "лидерборде", экспериментируя с моделями и задачами.
Тем не менее, даже в рамках XLand-MiniGrid существует пространство для экспериментов с мета-лёрнингом, в рамках которого можно найти AGI-архитектуру, удовлетворяющую всем необходимым требованиям.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/215